OpenStack — это платформа облачных вычислений с открытым исходным кодом, которая управляет распределенными вычислениями, сетью и хранилищем, объединяет их в пул ресурсов и позволяет пользователям настраивать виртуальные ресурсы через портал самообслуживания. Благодаря своей высокоэффективной масштабируемости он становится популярным при построении публичных облаков, снижая плату за обслуживание для поставщиков услуг и позволяя создавать сверхмасштабные инфраструктуры.
Хотя OpenStack помогает поставщикам услуг использовать крупномасштабную облачную платформу, никогда не следует упускать из виду аварийное восстановление.
Что такое аварийное восстановление (Disaster recovery) OpenStack
Виртуальные машины OpenStack можно использовать для поддержки производственных систем, поэтому их необходимо тщательно защищать. Существует несколько основных концепций аварийного восстановления OpenStack:
- Катастрофа: относится к внезапному событию, вызванному человеческими или природными факторами, которое приведет к серьезному сбою или полному сбою информационных систем в центре обработки данных. Это приведет к замедлению работы или остановке поддерживаемых бизнес-систем, и эти затронутые системы часто придется переключать на резервную площадку.
- Аварийное восстановление: относится к возможности восстановления приложений или бизнес-систем пострадавшего центра обработки данных во вторичном центре обработки данных.
- Устойчивость к катастрофам: означает, что кроме производственного центра обработки данных пользователям также необходимо построить еще один резервный центр обработки данных. В случае аварии производственный центр обработки данных может быть поврежден, поэтому производственные системы можно будет переключить в резервный центр обработки данных для обеспечения непрерывности бизнеса. Для повышения доступности многие пользователи построили более одного резервного центра обработки данных.
- RPO и RTO: относятся к двум основным факторам системы аварийного восстановления. RPO (Recovery Point Objective) означает допустимую потерю данных в случае аварии, а RTO (Recovery Time Objective). Более короткие TPO и RTO означают лучшие возможности аварийного восстановления и, конечно же, инвестиции также будут выше.
Уровень аварийного восстановления. Вообще говоря, существует 3 уровня:
- уровень данных,
- уровень приложения
- бизнес-уровень.
Уровень данных требует создания удаленного центра аварийного восстановления для хранения резервной копии данных , чтобы данные в основном центре обработки данных можно было восстановить в случае аварии;
Уровень приложений требует построения таких же систем приложений в удаленном центре аварийного восстановления и использует технологию репликации данных для обеспечения скорейшего восстановления приложений;
Бизнес-уровень требует построения практически такой же среды в удаленном центре аварийного восстановления для скорейшего восстановления бизнеса в случае катастрофы.
В средах OpenStack пользователи часто предпочитают резервное копирование и восстановление виртуальных машин. Если некоторые виртуальные машины выходят из строя, пользователи не смогут восстановить все хосты, поскольку это повлияет на другие работающие виртуальные машины. Простое восстановление вышедших из строя виртуальных машин на рабочем хосте просто решит проблему. Это работает только для аварийного восстановления на месте, а для аварийного восстановления за пределами предприятия пользователям по-прежнему необходимо создать удаленный центр аварийного восстановления для хранения резервных данных или перезапуска бизнес-систем.
Аварийное восстановление часто включает в себя HA (High Availability), который обеспечит непрерывность бизнеса путем переключения виртуальной машины с проблемного сервера на рабочий сервер. Для OpenStack HA резервирование узлов облачного контроллера, узла нейтронного контроллера, узла контроллера хранилища и вычислительного узла является самым основным требованием. В зависимости от особенностей и требований программного обеспечения, развернутого на каждом узле, к этим узлам будут применяться различные режимы высокой доступности.
Как сделать резервную копию и восстановить виртуальную машину OpenStack
Для создания высокоэффективной системы аварийного восстановления OpenStack необходимо мощное программное обеспечение. Vinchin — официальная организация поддержки OpenStack, а Vinchin Backup & Recovery может помочь в резервном копировании и восстановлении виртуальной машины OpenStack без использования агента.
Помимо базовой защиты данных, Vinchin Backup & Recovery также может облегчить аварийное восстановление OpenStack. Вам не нужно развертывать другое программное обеспечение для передачи данных резервного копирования виртуальной машины между основным сайтом и дополнительным сайтом. После того как вы создали задание резервного копирования виртуальной машины OpenStack в Vinchin Backup & Recovery, вы также можете создать задание для регулярного копирования данных резервной копии на вторичный сайт.
Кроме использования удаленного сайта, вы также можете отправить копию резервной копии в общедоступное облако, например Amazon S3, Microsoft Azure и т. д. Когда вам нужно восстановить виртуальную машину, просто загрузите данные резервной копии из облака.
Удобная веб-консоль поможет вам создать задание резервного копирования.
1. Выберите виртуальные машины OpenStack для резервного копирования
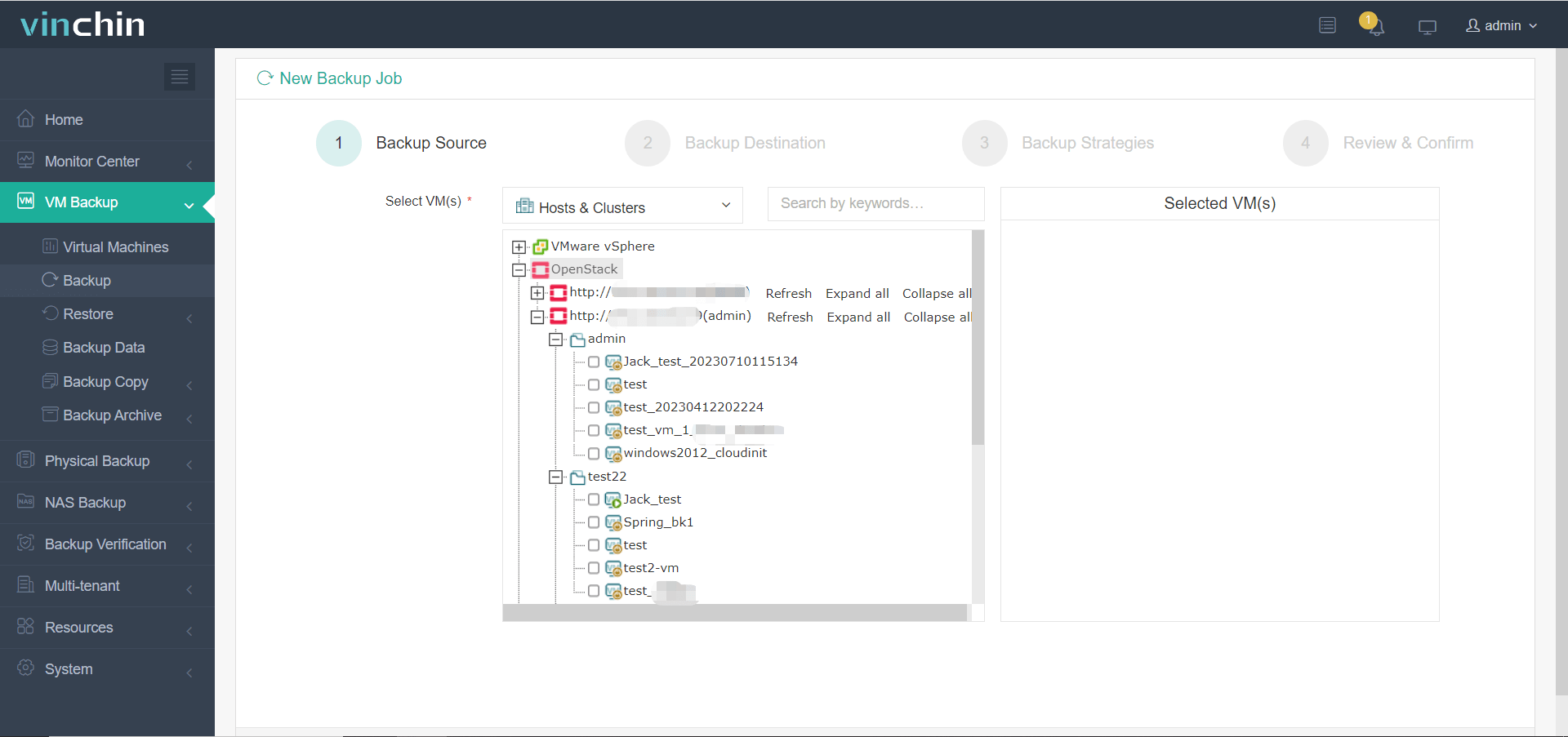
2. Выберите хранилище для хранения резервной копии OpenStack
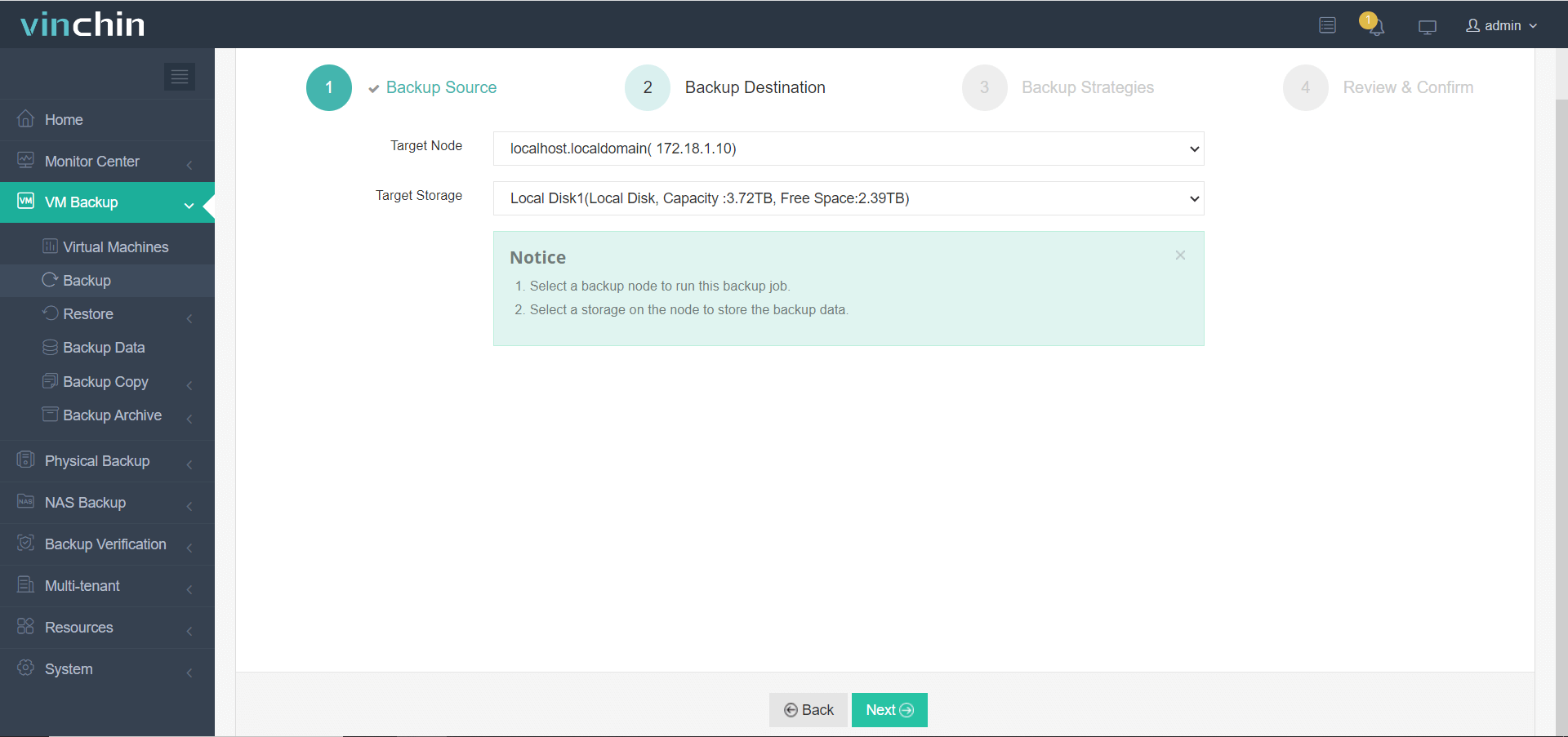
3. Выберите стратегию резервного копирования OpenStack
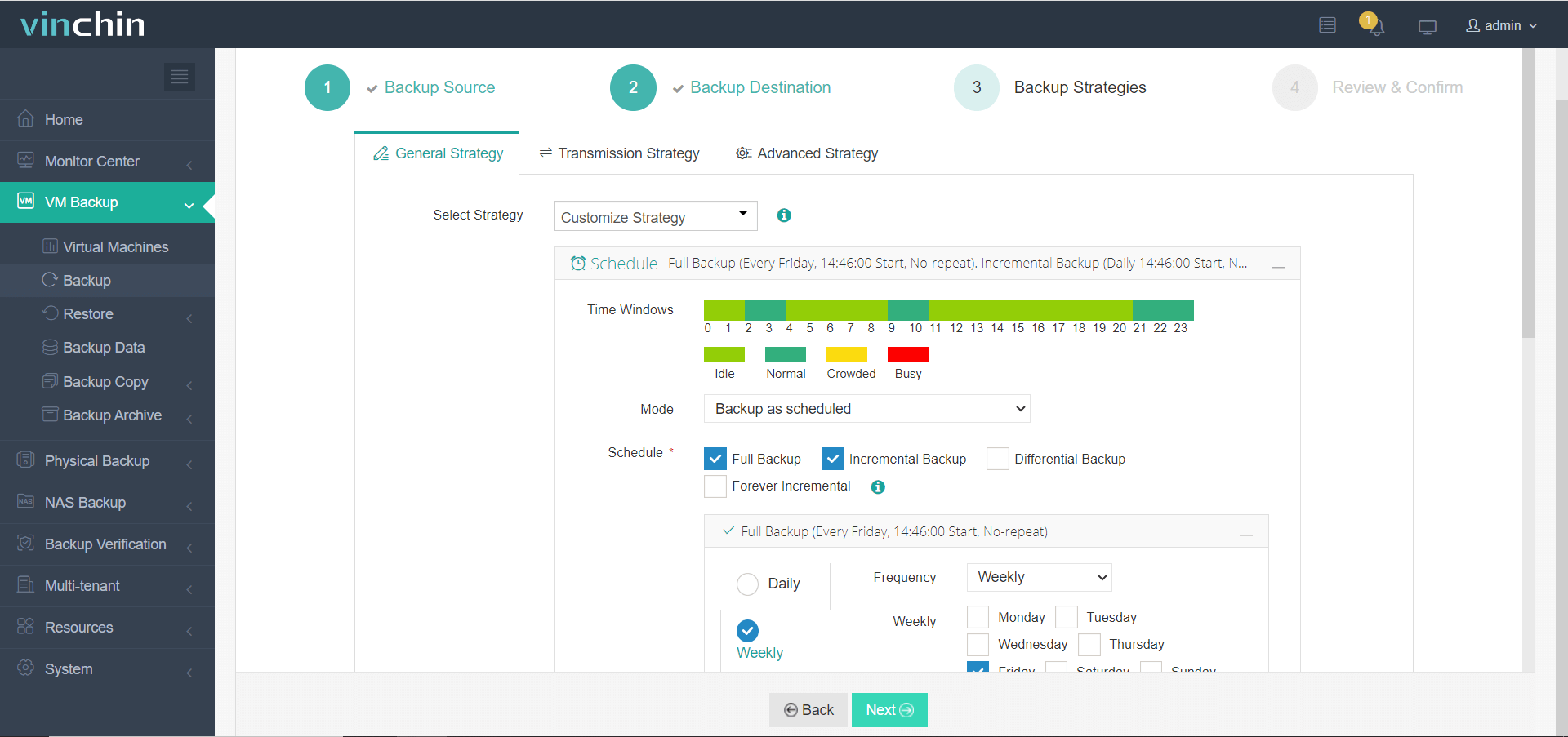
4. Запустите в работу задание резервного копирования OpenStack
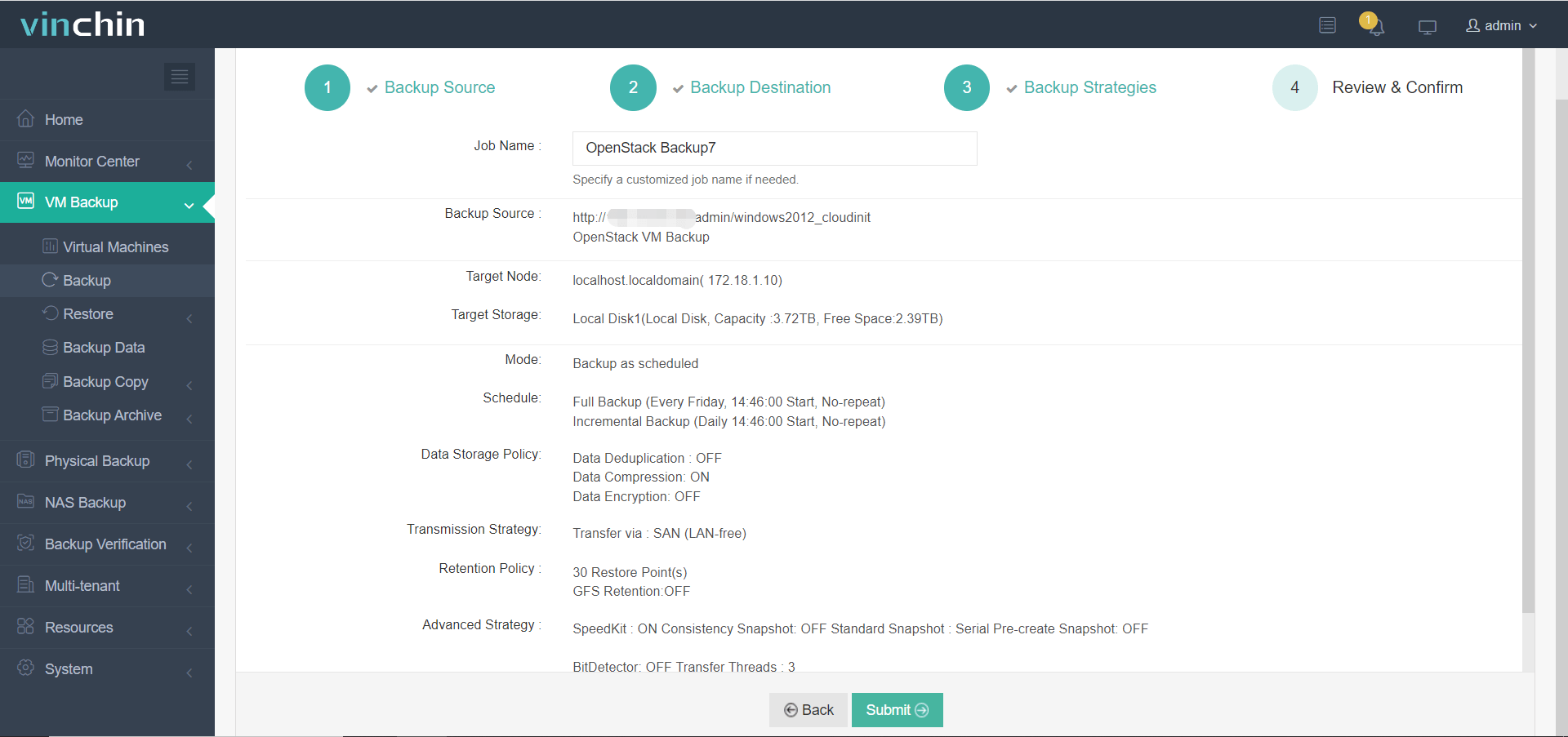
OpenStack — это инфраструктура облачных вычислений с открытым исходным кодом, широко используемая для крупномасштабных облачных вычислений, таких как телекоммуникации и ИТ-услуги. Чтобы защитить поддерживаемые им бизнес-системы, пользователям следует построить систему аварийного восстановления на случай любых катастроф, которые разрушают локальную систему и влияют на бизнес.
Vinchin Backup & Recovery — это официально проверенное решение для аварийного восстановления OpenStack, которое поможет легко создать высокоэффективную систему аварийного восстановления.
|
|
Внимание! Данная статья не является официальной документацией.Использование информации необходимо выполнять с осторожностью, используя для этого тестовую среду.
Если у вас есть вопросы о построении современных систем резервного копирования, репликации, синхронизации данных и защиты от программ вымогателей обратитесь в нашу компанию для получения консультации о современных технологиях резервного копирования и восстановления данных. Наша компания имеет более чем 20-летний опыт в этой области. |
||||

Десять лучших практик Vinchin
- 4 способа резервного копирования экземпляров AWS EC2
- Как сделать инкрементную резервную копию oVirt
- Что такое балансировка нагрузки Hyper-V и как ее настроить
- Как выполнить аварийное восстановление XCP-ng
- Как перенести виртуальные машины с VMware на XCP-ng
- Что такое XenConvert и какие существуют альтернативы
- Sangfor HCI против VMware: всестороннее сравнение
- High Availability против Disaster Recovery. Давайте разберемся
- Что такое файл OVA и файл OVF. Шаблоны виртуальных машин
- Как перенести виртуальную машину из Proxmox в XCP-ng
